Alexander Panchenko
Natural Language Processing Laboratory
Center for Artificial Intelligence Technology
Hello, I am Alexander, an assistant professor for Natural Language Processing (NLP). My main research interest is computational lexical semantics, including word sense embeddings, word sense induction, extraction of lexical resources, and other related topics. I am also interested in argument mining. More generally, I am interested in neural and statistical natural language processing, information retrieval, knowledge bases, machine learning and intersections/interactions of these fields. You can find the list of my publications below on this page and also at Google Scholar.
I am with the Skoltech since 2019. My background is almost a decade of exciting research and developments in the field of NLP: I worked on a range of problems and tasks, such as semantic relatedness, word sense disambiguation, and induction, sentiment analysis, gender detection, taxonomy induction, etc . Before Skoltech, I was a Postdoctoral researcher in the group of Chris Biemann at the University of Hamburg, Germany. Prior to the appointment in Hamburg, I had a position of Postdoc at TU Darmstadt. I received my PhD in Computational Linguistics from the Université catholique de Louvain, Belgium. During these years, I (co-)authored more than 40 peer-reviewed research publications, including papers in top-tier conference proceedings, such as ACL, EMNLP, EACL, and ECIR receiving (with co-authors) the best paper awards at the “Representation Learning for NLP” (RepL4NLP) workshop at ACL 2016 and SemEval’2019 competition on “Unsupervised Frame Induction”. I co-organised two shared tasks on semantic relatedness and word sense induction evaluation for the Russian language (RUSSE’15 and RUSSE’18). I served also as a co-editor of a data science conference on Analysis of Social Networks, Images, and Texts (AIST) with the proceedings published in Springer LNCS series.
Information for prospective students willing to do a research project on a topic related to NLP.
Below is a list of some selected research highlights in grouped by fields of interest. The full list of references can be found on the publication tab.
Lexical Semantics
| Idea: | To induce sense inventories for 158 languages and design a word sense disambiguation (WSD) algorithm for them using only word embeddings with no training data. These way we enable WSD for low-resourced languages. |
| Paper: | Word Sense Disambiguation for 158 Languages using Word Embeddings Only (LREC-2020) |
| Illustration: |  |
| Ideas: | (1) To perform lexical substitution in context, integration of information about the target work is important; (2) The majority of the lexical substitutes are co-hyponyms and synonyms, but the distribution varies across parts of speeches and models. |
| Paper: | Always Keep your Target in Mind: Studying Semantics and Improving Performance of Neural Lexical Substitution (COLING-2020) |
| Illustration: | 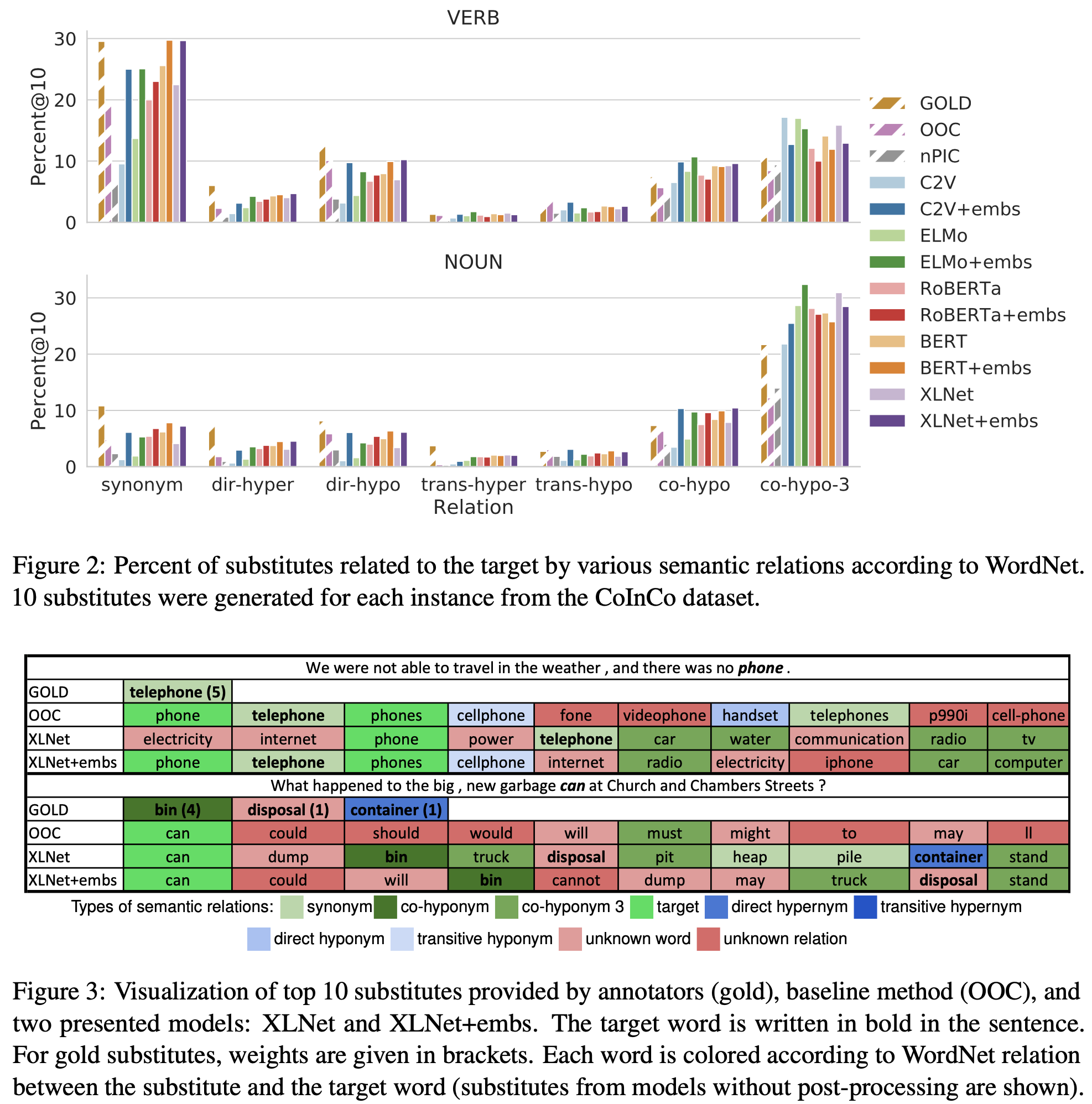 |
| Idea: | Induce from text interpretable representations of word senses fitted with images, hypernyms, definitions, and so on in a completely unsupervised fashion and design a system for word sense disambiguation on the basis of this sense inventory. |
| Reference: | Unsupervised, Knowledge-Free, and Interpretable Word Sense Disambiguation (EMNLP-2017) |
| Illustration: | 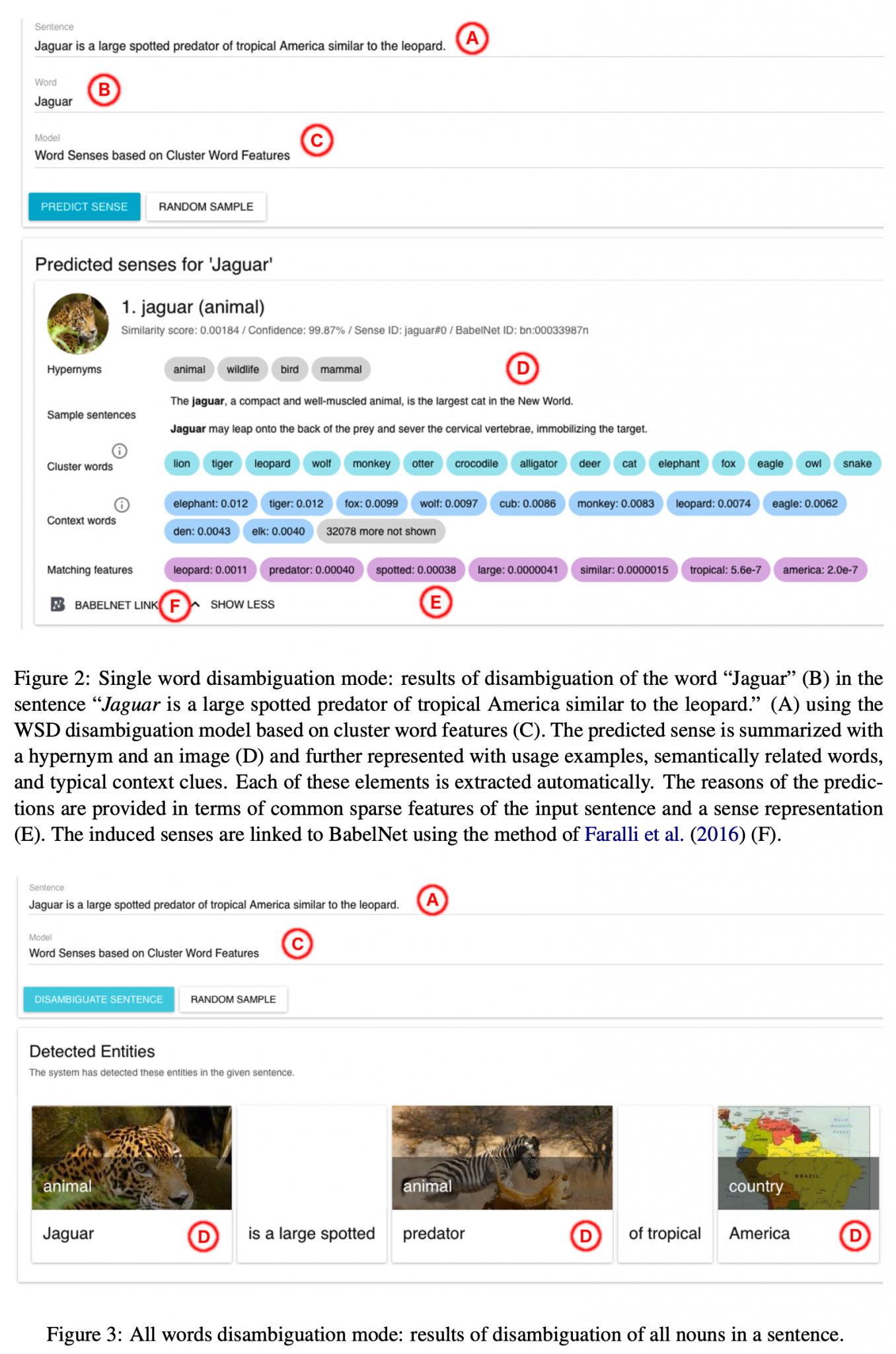 |
| Idea: | Similarly to a social ego-network, where an individual has several circles of close groups that do not overlap, related words cluster in a similar way forming word senses. An ego-network based graph clustering can be used to automatically identify word senses based on any pre-trained word embedding model. |
| Paper: | Making Sense of Word Embeddings (ACL-2016) |
| Illustration: | 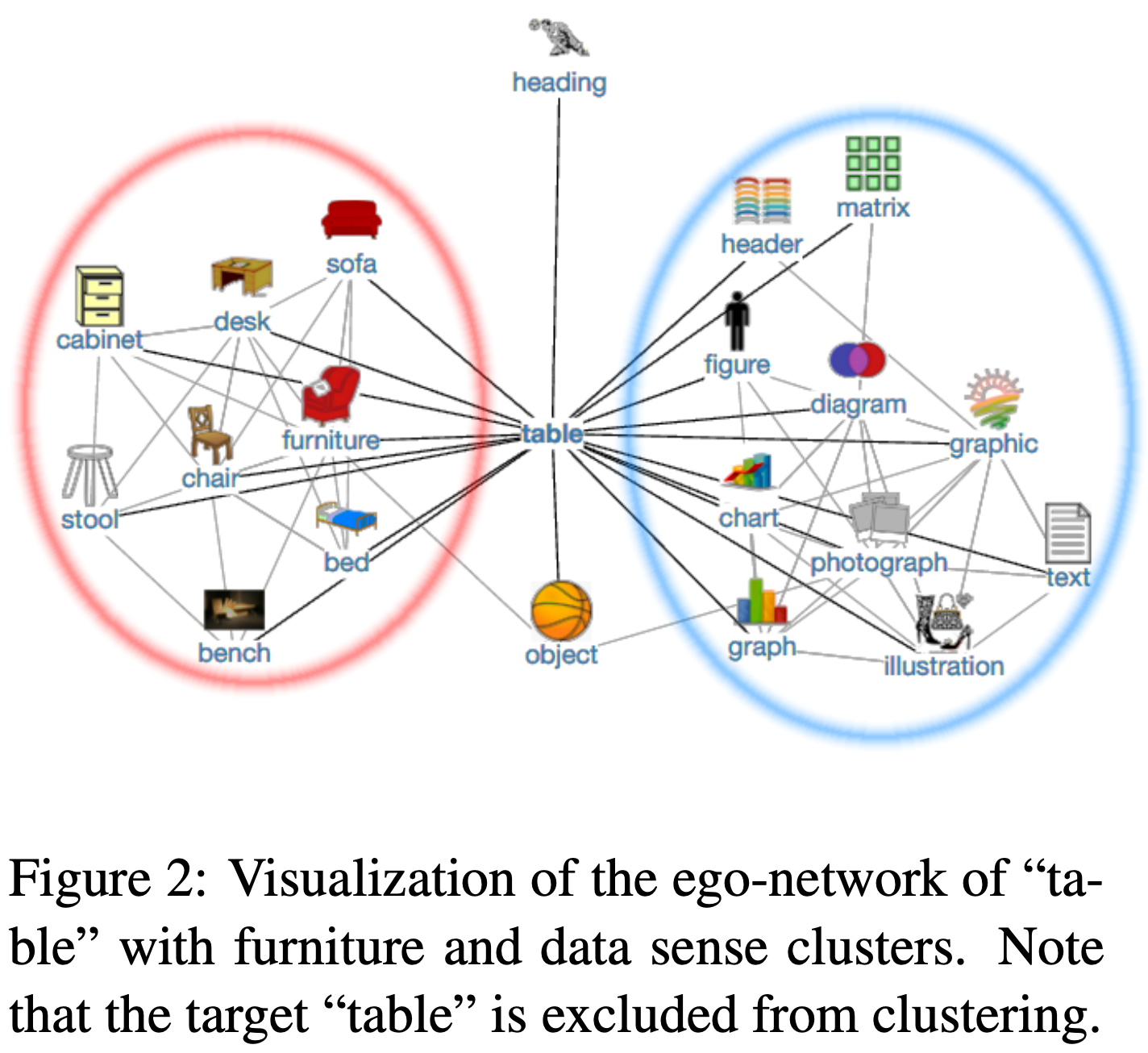 |
Argument Mining
| Idea: | It is possible to mine the Web for comparative statements to help to answer comparative questions (like “Is python better than Matlab for deep learning?”) and design a system that would fulfill the information needs of the users more efficiently than the usual web search. |
| Paper: | Answering Comparative Questions: Better than Ten-Blue-Links? (CHIIR-2019) |
| Illustration: | 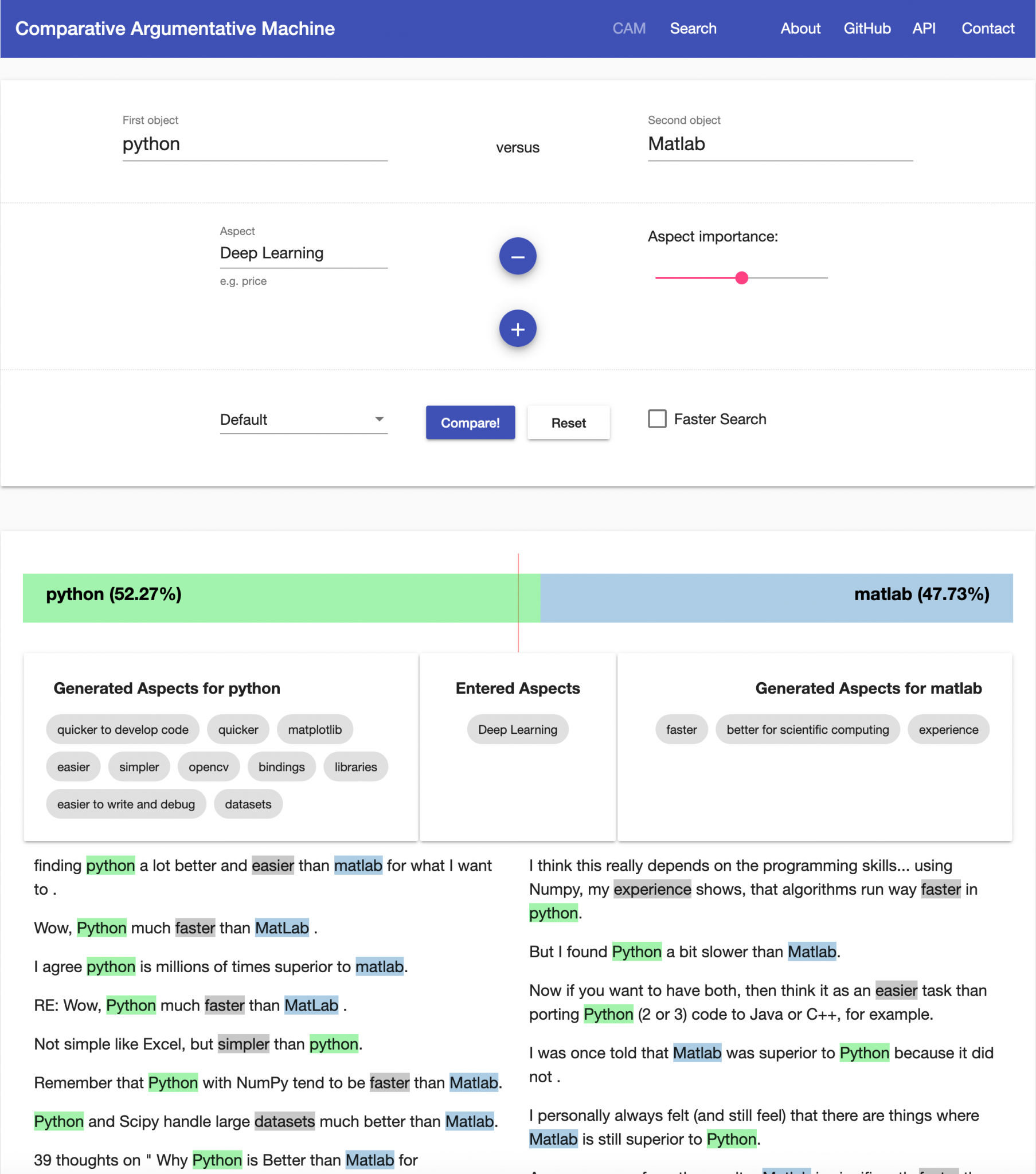 |
| Idea: | Argument mining can be cast as a tagging task, we make available the recent neural models readily available for the integration into various NLP pipelines as well as for interactive analysis of user texts. |
| Paper: | TARGER: Neural Argument Mining at Your Fingertips (ACL-2019) |
| Illustration: |  |
List of the Main Research Interests
A more complete list of research interests is listed below:
- Lexical semantics (especially word sense induction and disambiguation, frame induction and disambiguation, semantic similarity and relatedness, sense embeddings, automated construction and completion of lexical resources such as WordNet and FrameNet)
- Argument mining (especially comparative argument mining, and argument retrieval)
- Learning representations of linguistic symbolic structures (graphs) such as knowledge bases and lexical resource
- NLP for a better society: recognition of fake news, hate speech, and related phenomena
- Textual style transfer
Monographs
- Alexander Panchenko (2013): Similarity Measures for Semantic Relation Extraction, PhD Thesis, Université catholique de Louvain
- Alexander Panchenko (2008): Automatic Thesaurus Construction System, Graduation Thesis, Moscow State Technical University (BMSTU)
Edited volumes
- Panchenko, A., Malliaros, F. D., Logacheva, V., Jana, A., Ustalov, D., & Jansen, P. (2021). Proceedings of the Fifteenth Workshop on Graph-Based Methods for Natural Language Processing (TextGraphs-15). In Proceedings of the Fifteenth Workshop on Graph-Based Methods for Natural Language Processing (TextGraphs-15). Association for Computational Linguistics (ACL).
- Shalom, O. S., Panchenko, A., dos Santos, C., Logacheva, V., Moschitti, A., & Dagan, I. (2020). Proceedings of Knowledgeable NLP: the First Workshop on Integrating Structured Knowledge and Neural Networks for NLP. In Proceedings of Knowledgeable NLP: the First Workshop on Integrating Structured Knowledge and Neural Networks for NLP. Association for Computational Linguistics (ACL).
- Ustalov, D., Somasundaran, S., Panchenko, A., Malliaros, F. D., Hulpuș, I., Jansen, P., & Jana, A. (2020). Proceedings of the Graph-based Methods for Natural Language Processing (TextGraphs-14). Association for Computational Linguistics (ACL).
- van der Aalst, W.M.P., Batagelj, V., Panchenko, A., Ignatov, D.I., Khachay, M., Kuznetsov, S.O., Koltsova O., Lomazova, I.A., Loukachevitch, N., Napoli, A., Panchenko, A., Pardalos, Pelillo, M., Savchenko, A.V. (Eds.) (2020): The 9th International Conference on Analysis of Images, Social Networks and Texts(AIST’2020), Moscow, Russia, October 15–16, 2018, Revised Selected Papers. Springer Lecture Notes in Computer Science (LNCS). Springer
- van der Aalst, W.M.P., Batagelj, V., Buzmakov, A., Ignatov, D.I., Kalenkova, A., Khachay, M., Koltsova, O., Kutuzov, A., Kuznetsov, S.O., Lomazova, I.A., Loukachevitch, N., Makarov, I., Napoli, A., Panchenko, A., Pardalos, P.M., Pelillo, M., Savchenko, A.V., Tutubalina, E. (Eds.)(2020): Recent Trends in Analysis of Images, Social Networks and Texts. 9th International Conference, AIST 2020, Skolkovo, Moscow, Russia, October 15–16, 2020 Revised Supplementary Proceedings. Communications in Computer and Information Science (CCIS). Springer International Publishing
- van der Aalst, W.M.P., Batagelj, V., Glavaš, G., Ignatov, D.I., Khachay, M., Kuznetsov, S.O., Koltsova O., Lomazova, I.A., Loukachevitch, N., Napoli, A., Panchenko, A., Pardalos, Pelillo, M., Savchenko, A.V. (Eds.) (2018) The 7th International Conference on Analysis of Images, Social Networks and Texts (AIST’2018), Moscow, Russia, July 5–7, 2018, Revised Selected Papers. Springer Lecture Notes in Computer Science (LNCS). Springer
- van der Aalst, W.M.P., Ignatov, D.I., Khachay, M., Kuznetsov, S.O., Lempitsky, V., Lomazova, I.A., Loukachevitch, N., Napoli, A., Panchenko, A., Pardalos, P.M., Savchenko, A.V., Wasserman, S. (Eds.) (2017) The 6th International Conference on Analysis of Images, Social Networks and Texts (AIST’2017), Moscow, Russia, July 27–29, 2017, Revised Selected Papers. Springer Lecture Notes in Computer Science (LNCS). Springer
- Ignatov, D.I., Khachay, M.Y., Labunets, V.G., Loukachevitch, N., Nikolenko, S., Panchenko, A., Savchenko, A.V., Vorontsov, K. (Eds.) (2016) The 5th International Conference on Analysis of Images, Social Networks and Texts (AIST’2016), Yekaterinburg, Russia, April 7-9, Revised Selected Papers. Communications in Computer and Information Science. Springer Heidelberg Dordrecht London New York.
- Baixeries J., Ignatov D.I., Ilvovsky D., Panchenko A. (Eds.) (2016) The 3rd International Workshop on Concept Discovery in Unstructured Data (CDUD’2016) co-located with the 13th International Conference on Concept Lattices and Their Applications (CLA 2016), July 18, 2016, Moscow, Russia. CEUR-Workshop, Vol. 1625, ISSN 1613-0073.
- Ignatov D.I., Khachay M.Y., Labunets V.G., Loukachevitch N., Nikolenko S., Panchenko A., Savchencko A.V., Vorontosov K.V. (2016) Supplementary Proceedings of the Fifth International Conference on Analysis of Images, Social Networks and Texts (AIST-SUP 2016). Yekaterinburg, Russia, April 6-8, 2016. CEUR-WS, Vol 1710. ISSN 1613-0073
- Khachay, M.Y., Konstantinova, N., Panchenko, A., Ignatov, D.I., Labunets, V.G. (Eds.) (2015) The 4th International Conference on Analysis of Images, Social Networks and Texts (AIST’2014), Yekaterinburg, Russia, April 9-11, Revised Selected Papers. Communications in Computer and Information Science. Springer Heidelberg Dordrecht London New York.
- Ignatov, D.I., Khachay, M.Y., Panchenko, A., Konstantinova, N., Yavorsky, R.E. (Eds.) (2014). The 3rd International Conference on Analysis of Images, Social Networks and Texts (AIST’2014), Yekaterinburg, Russia, April 10-12, Revised Selected Papers. Communications in Computer and Information Science. Springer Heidelberg Dordrecht London New York.
Journal articles
- Sevgili, O., Shelmanov, A., Arkhipov, M., Panchenko, A., and Biemann, C. (2022): Neural Entity Linking: A Survey of Models Based on Deep Learning. In Semantic Web journal. IOS Press.
- Nikishina, I., Tikhomirov, M., Logacheva, V., Nazarov, Y., Panchenko, A., and Loukachevitch, N. (2022): Taxonomy Enrichment with Text and Graph Vector Representations. In Semantic Web journal. IOS Press.
- Dementieva, D.; Moskovskiy, D.; Logacheva, V.; Dale, D.; Kozlova, O.; Semenov, N.; Panchenko, A. Methods for Detoxification of Texts for the Russian Language. Multimodal Technol. Interact. 2021, 5, 54.
- Bondarenko, A., Panchenko, A., Beloucif, M., Biemann, C., and Hagen, M. (2020): Answering Comparative Questions with Arguments. Datenbank Spektrum (2020). Springer.
- Ustalov, D., Panchenko., A., Biemann., C., Ponzetto. S. (2019): Watset: Local-Global Graph Clustering with Applications in Sense and Frame Induction. Computational Linguistics. MIT Press.
- Biemann, C., Faralli, S., Panchenko, A., Ponzetto, S.P. (2018): A framework for enriching lexical semantic resources with distributional semantics. Journal of Natural Language Engineering, published online Jan 15, 2018
Conference proceedings
-
Dale, D., Voronov, A., Dementieva, D., Logacheva, V., Kozlova, O., Semenov, N. and Panchenko, A. (2021): Text Detoxification using Large Pre-trained Neural Models. In Proceedings of 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP-2021). Punta Cana, Dominican Republic.
- Vorona, I., Phan, A.-H., Panchenko, A., Cichocki, A. (2021): Documents Representation via Generalized Coupled Tensor Chain with the Rotation Group Constraint. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics. Bangkok, Thailand (Online)
- Dementieva, D. and Panchenko, A. (2021): Cross-lingual Evidence Improves Monolingual Fake News Detection. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP): Student Research Workshop. Association for Computational Linguistics. Bangkok, Thailand (Online)
- Dementieva, D., Moskovskiy, D., Logacheva, V., Dale, D., Kozlova, O., Semenov, N., and Panchenko, A. (2021): Methods for Detoxification of Texts for the Russian Language. Computational Linguistics and Intellectual Technologies: Proceedings of the International Conference “Dialogue 2021”. Moscow, Russia (Online)
-
Chekalina, V., Bondarenko, A., Biemann, C., Beloucif, M., Logacheva, V., Panchenko, A. (2021): Which is better for Deep Learning: Python or MATLAB? Answering Comparative Questions in Natural Language. The 2021 Conference of the European Chapter of the Association for Computational Linguistics – System Demonstrations. Kyiv, Ukraine (Online)
- Bondarenko, A., Gienapp, L., Fröbe, M., Beloucif, M., Ajjour,Y., Panchenko, A., Biemann,C., Stein, B., Wachsmuth, H., Potthast, M., Hagen, M. (2021): Overview of Touché 2021: Argument Retrieval. Extended Abstract. Proceedings of ECIR 2021, Lucca, Italy (Online)
- Shelmanov, A., Puzyrev, D., Kupriyanova, L., Belyakov, D., Larionov, D., Khromov, N., Kozlova, O., Artemova, E. Dylov, D. V., and Panchenko A. (2021): Active Learning for Sequence Tagging with Deep Pre-trained Models and Bayesian Uncertainty Estimates. In Proceeding of the 16th conference of the European Chapter of the Association for Computational Linguistics (EACL). Kiev, Ukraine (online).
- Shelmanov, A., Tsymbalov, E., Puzyrev, D., Fedyanin, K., Panchenko, A., Panov, M. (2021): How Certain is Your Transformer? In Proceeding of the 16th conference of the European Chapter of the Association for Computational Linguistics (EACL). Kiev, Ukraine (online).
- Nikishina, I., Logacheva, V., Loukachevitch N., and Panchenko, A. (2021): Exploring Graph-based Representations for Taxonomy Enrichment. In Proceedings of the Global WordNet Conference. Pretoria, South Africa (Online)
- Arefyev, N., Sheludko, B., Podolskiy, A., and Panchenko A. (2020): Always Keep your Target in Mind: Studying Semantics and Improving Performance of Neural Lexical Substitution. In Proceedings of the 28th International Conference on Computational Linguistics (COLING-2020). Barcelona, Spain.
- Nikishina, I., Logacheva, V., Panchenko, A., and Loukachevitch N. (2020): Studying Taxonomy Enrichment on Diachronic WordNet Versions. In Proceedings of the 28th International Conference on Computational Linguistics (COLING-2020). Barcelona, Spain.
- Chistova, E., Shelmanov, A., Pisarevskaya, D., Kobozeva, M., Toldova, S., Panchenko, A., and Smirnov I. (2020): RST Discourse Parser for Russian: Experimental Study of Deep Learning Models. In Proceedings of the 9-th International Conference on Analysis of Images, Social Networks, and Texts (AIST-2020). Springer Lecture Notes in Computer Science (LNCS). Moscow, Russia.
- Dementieva D. and Panchenko A. (2020): Fake News Detection using Multilingual Evidence. The 7th IEEE International Conference on Data Science and Advanced Analytics (DSAA-2020). Sydney, Australia
- Logacheva, V., Teslenko, D., Shelmanov, A., Remus, S., Ustalov, D., Kutuzov, A., Artemova, E., Biemann, C., Ponzetto, S.P., Panchenko, A. (2020): Word Sense Disambiguation for 158 Languages using Word Embeddings Only. Proceedings of the International Conference on Language Resources and Evaluation (LREC 2020), Marseille, France
- Anwar, S., Shelmanov, A., Panchenko, A. and Biemann C. (2020): Generating Lexical Representations of Frames using Lexical Substitution. Proceedings of the International Conference on Probability and Meaning (PaM ) 2020, Gothenburg, Sweden
- Bondarenko, A., Hagen, M., Potthast, M., Wachsmuth, H., Beloucif, M., Biemann, C., Panchenko, A., Stein, B. (2020): Touché: First Shared Task on Argument Retrieval. Proceedings of ECIR 2020 Clef Task papers, Lisbon, Portugal
- Bondarenko, A., Braslavski, P., Völske, M., Aly, R., Fröbe, M., Panchenko, A., Biemann, C., Stein, B., Hagen, M. (2020): Comparative Web Search Questions. The 13th ACM International WSDM Conference, Houston, Texas, USA
- Puzyrev, D., Shelmanov, A., Panchenko, A., Artemova, E. (2019): Noun Compositionality Detection Using Distributional Semantics for the Russian Language. Proceedings of the 8-th conference on Analysis of Images, Social Networks and Texts (AIST’2019). Springer Lecture Notes in Computer Science. Kazan, Russia.
- Liventsev, V., Shelmanov, A., Kireev, D., Khromov, N., Panchenko, A., & Dylov, D. (2019). Active learning with deep pre-trained models for sequence tagging of clinical and biomedical texts. In 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM’2019). San Diego, CA, USA.
- Arefyev N., Sheludko B., and Panchenko A. (2019): Combining Lexical Substitutes in Neural Word Sense Induction. In Proceedings of the 12th International Conference on Recent Advances in Natural Language Processing. pp.62-70. Varna, Bulgaria
- Jana, A., Puzyrev, D., Panchenko, A., Goyal, P., Biemann, C., Mukherjee, A. (2019): On the Compositionality Prediction of Noun Phrases using Poincaré Embeddings. Proceedings of ACL 2019 (full papers), Florence, Italy
- Kutuzov, A., Dorgham, M, Oliynyk, O., Biemann, C., Panchenko, A. (2019): Making Fast Graph-based Algorithms with Graph Metric Embeddings. Proceedings of ACL 2019 (short papers), Florence, Italy
- Aly, R., Acharya, S., Ossa, A., Köhn, A., Biemann, C., Panchenko, A. (2019): Every child should have parents: a taxonomy refinement algorithm based on hyperbolic term embeddings. Proceedings of ACL 2019 (short papers), Florence, Italy
- Chernodub, A., Oliynyk, O., Heidenreich, P., Bondarenko, A., Hagen, M., Biemann, C., Panchenko, A. (2019): TARGER: Neural Argument Mining at Your Fingertips. Proceedings of ACL 2019 (demo papers), Florence, Italy
- Sevgili, Ö., Panchenko, A., Biemann, C. (2019): Improving Neural Entity Disambiguation with Graph Embeddings. Proceedings of the ACL 2019 Student Research Workshop, Florence, Italy
- Kutuzov, A., Dorgham, M., Oliynyk, O., Panchenko, A. and Biemann, C. (2019): Learning Graph Embeddings from WordNet-based Similarity Measures. Proceedings of *SEM, Minneapolis, MN, USA
- Schildwächter, M., Bondarenko, A., Zenker, J., Hagen, M., Biemann, C., Panchenko, A. (2019): Answering Comparative Qestions: Better than Ten-Blue-Links? Proceedings of ACM SIGIR Conference on Human Information Interaction and Retrieval (CHIIR), Glasgow, Scotland, UK
- Ustalov, D., Panchenko, A., Biemann, C., Ponzetto, S.P. (2018): Unsupervised Sense-Aware Hypernymy Extraction. Proceedings of the 14th Conference on Natural Language Processing (KONVENS 2018) Vienna, Austria
- Ustalov, D., Panchenko, A., Kutuzov, A., Biemann, C., Ponzetto, S.P. (2018): Unsupervised Semantic Frame Induction using Triclustering. Proceedings of ACL 2018, Melbourne, Australia
- Panchenko A., Lopukhina A., Ustalov D., Lopukhin K., Arefyev N., Leontyev A., Loukachevitch N. (2018): RUSSE’2018: A Shared Task on Word Sense Induction for the Russian Language. In Proceedings of the 24th International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2018). Moscow, Russia. RGGU
- Arefyev, N., Ermolaev, P., Panchenko. A. (2018): How much does a word weigh? Weighting word embeddings for word sense induction. In Proceedings of the 24th International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2018). Moscow, Russia. RGGU
- Panchenko, A., Ruppert, E., Faralli, S., Ponzetto, S.P., Biemann, C. (2018): Building a Web-Scale Dependency-Parsed Corpus from Common Crawl. Proceedings of LREC 2018, Myazaki, Japan
- Ustalov, D., Teslenko, D., Panchenko, A., Chernoskutov, M., Biemann, C., Ponzetto, S.P. (2018): An Unsupervised Word Sense Disambiguation System for Under-Resourced Languages. Proceedings of LREC 2018, Myazaki, Japan
- Faralli, S., Panchenko, A., Biemann, C., Ponzetto, S.P. (2018): Enriching Frame Representations with Distributionally Induced Senses. Proceedings of LREC 2018, Myazaki, Japan
- Panchenko, A., Ustalov, D., Faralli, S., Ponzetto, S.P., Biemann, C. (2018): Improving Hypernymy Extraction with Distributional Semantic Classes. Proceedings of LREC 2018, Myazaki, Japan
- Panchenko A., Fide M., Ruppert E., Faralli S., Ustalov D., Ponzetto S.P., Biemann C. (2017): Unsupervised, Knowledge-Free, and Interpretable Word Sense Disambiguation. In Proceedings of the the Conference on Empirical Methods on Natural Language Processing (EMNLP). Copenhagen, Denmark. Association for Computational Linguistics
- Ustalov D., Chernoskutov M., Biemann C., Panchenko A.: Fighting with the Sparsity of Synonymy Dictionaries. In Proceedings of the 6th Conference on Analysis of Images, Social Networks, and Texts (AIST’2017): Springer Lecture Notes in Computer Science (LNCS). Moscow, Russia
- Ustalov D., Panchenko A., Biemann C. (2017): Watset: Automatic Induction of Synsets from a Graph of Synonyms. In Proceedings of the 55th Meeting of the Association for Computational Linguistics (ACL’2017). Vancouver, Canada. Association for Computational Linguistics
- Ustalov D., Arefyev N., Biemann C., Panchenko A. (2017): Negative Sampling Improves Hypernymy Extraction Based on Projection Learning. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL’2017). Valencia, Spain. Association for Computational Linguistics
- Faralli S., Panchenko A., Biemann C., and Ponzetto S. P. (2017): The ContrastMedium Algorithm: Taxonomy Induction From Noisy Knowledge Graphs With Just A Few Links. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL’2017). Valencia, Spain. Association for Computational Linguistics.
- Panchenko A., Ruppert E., Faralli S., Ponzetto S. P., and Biemann C. (2017): Unsupervised Does Not Mean Uninterpretable: The Case for Word Sense Induction and Disambiguation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL’2017). Valencia, Spain. Association for Computational Linguistics.
- Faralli S., Panchenko A., Biemann C., Ponzetto S. P. (2016): Linked Disambiguated Distributional Semantic Networks. In Proceedings of the 15th International Semantic Web Conference (ISWC 2016). pp. 56-64, Kobe, Japan. Lecture Notes in Computer Science, Springer International Publishing
- Ustalov D., Panchenko A. (2016): Learning Word Subsumption Projections for the Russian Language. In Proceedings of the International Conference on Big Data and its Applications (ICBDA 2016). ITM Web of Conferences. Vol. 8. P.01006. dx.doi.org/10.1051/itmconf/20160801006
- Panchenko A., Simon J., Riedl M., Biemann C. (2016): Noun Sense Induction and Disambiguation using Graph-Based Distributional Semantics. In Proceedings of the 13th Conference on Natural Language Processing (KONVENS’2016). Bochum, Germany. Bochumer Linguistische Arbeitsberichte (BLA)
- Yimam S.M., Ulrich H., von Landesberger T., Rosenbach M., Regneri M., Panchenko A., Lehmann F., Fahrer U., Biemann C. Ballweg K. (2016): new/s/leak – Information Extraction and Visualization for Investigative Data Journalists. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL). System Demonstrations. Berlin, Germany. Association for Computational Linguistics [Best paper award of Fraunhofer IGD and Visual Computing Groups of TU Darmstadt]
- Panchenko A. (2016): Best of Both Worlds: Making Word Sense Embeddings Interpretable. In Proceedings of the 10th edition of the Language Resources and Evaluation Conference (LREC’2016), Portorož, Slovenia. European Language Resources Association (ELRA)
- Panchenko A., Ustalov D., Arefyev N., Paperno D. Konstantinova N., Loukachevitch N. and Biemann C. (2016): Human and Machine Judgements about Russian Semantic Relatedness. In Proceedings of the 5th Conference on Analysis of Images, Social Networks, and Texts (AIST’2016). Communications in Computer and Information Science (CCIS). Springer-Verlag Berlin Heidelberg
- Panchenko A., Babaev D., and Objedkov S. (2015): Large-Scale Parallel Matching of Social Network Profiles. In Proceedings of 4th Conference on Analysis of Images, Social Networks, and Texts. Yekaterinburg, Russia. Communications in Computer and Information Science (CCIS). Springer-Verlag Berlin Heidelberg
- Panchenko A., Loukachevitch N. V., Ustalov D., Paperno D., Meyer C. M., Konstantinova N. (2015): RUSSE: The First International Workshop on Russian Semantic Similarity. In Proceedings of the 21st International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2015). Moscow, Russia. RGGU
- Arefyev N., Panchenko A., Lukanin A., Lesota O., Romanov P. (2015): Evaluating Three Corpus-Based Semantic Similarity Systems for Russian. In Proceedings of the 21st International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2015). Moscow, Russia. RGGU
- Panchenko A. (2014): Sentiment Index of the Russian Speaking Facebook. In Proceedings of the 20th International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2014). Moscow, Russia. RGGU
- Panchenko A., Muraviev N., Objedkov S. (2014): Neologisms on Facebook. In Proceedings of the 20th International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2014). Moscow, Russia. RGGU
- Panchenko A., Teterin A. (2014): Gender Detection by Full Name: Experiments with the Russian Language. In Proceedings of 3rd Conference on Analysis of Images, Social Networks, and Texts. Communications in Computer and Information Science (CCIS) Volume 436, pp.169-182. Springer-Verlag Berlin Heidelberg
- Panchenko A., Naets H., Brouwers L., Romanov P., Fairon C. (2013): Recherche et visualization de mots sémantiquement liés. In Proceedings of the 20th French Conference on Natural Language Processing (Conférence sur le Traitement Automatique des Langues Naturelles, TALN’2013). Les Sables d’Olonne, France. pp.747–754. Association pour le Traitement Automatique des Langues (ATALA)
- Panchenko A., Naets H., Beaufort R., Fairon C. (2013): Towards Detection of Child Sexual Abuse Media: Classification of the Associated Filenames. In Proceedings of the 35th European Conference on Information Retrieval (ECIR’2013). Lecture Notes in Computer Science (LNCS) vol. 7814, pp. 776-779. Springer-Verlag Berlin Heidelberg
- Panchenko A., Romanov P., Morozova O., Naets H., Romanov A., Philippovich A., Fairon C. (2013): Serelex: Search and Visualization of Semantically Similar Words. In Proceedings of the 35th European Conference on Information Retrieval (ECIR’2013). Lecture Notes in Computer Science (LNCS) vol. 7814, pp. 837-840. Springer-Verlag Berlin Heidelberg
- Panchenko A., Morozova O., Naets H. (2012): A Semantic Similarity Measure Based on Lexico-Syntactic Patterns. In Proceedings of the 11th Conference on Natural Language Processing (KONVENS’2012). pp.174–178. Vienna, Austria. Österreichische Gesellschaft für Artificial Intelligence (ÖGAI)
- Panchenko A. (2012): A Study of Heterogeneous Similarity Measures for Semantic Relation Extraction. In Proceedings of 14th French Conference on Natural Language Processing (JEP-TALN-RECITAL). Grenoble, France. Association pour le Traitement Automatique des Langues (ATALA)
Workshop proceedings
- Chekalina, V., Panchenko (2021): Retrieving Comparative Arguments using Ensemble Methods and Neural Information Retrieval. Proceedings of the Working Notes of CLEF 2021 – Conference and Labs of the Evaluation Forum. Bucharest, Romania.
- Dementieva, D., Ustyantsev, S., Dale, D., Kozlova, O., Semenov, N., Panchenko, A., and Logacheva, V. (2021): Crowdsourcing of Parallel Corpora: the Case of Style Transfer for Detoxification. Proceedings of the 2nd Crowd Science Workshop: Trust, Ethics, and Excellence in Crowdsourced Data Management at Scale co-located with 47th International Conference on Very Large Data Bases (VLDB 2021) . Copenhagen, Denmark
- Razzhigaev, A., Arefyev, N., Panchenko, A. (2021): SkoltechNLP at SemEval-2021 Task 2: Generating Cross-Lingual Training Data for the Word-in-Context Task. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021). Association for Computational Linguistics. Bangkok, Thailand (Online)
- Dale, D., Markov, I., Logacheva, V., Kozlova, O., Semenov, N., Panchenko, A. (2021): SkoltechNLP at SemEval-2021 Task 5: Leveraging Sentence-level Pre-training for Toxic Span Detection. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021). Association for Computational Linguistics. Bangkok, Thailand (Online)
- Dementieva, D., Moskovskiy, D., Logacheva, V., Dale, D., Kozlova, O., Semenov, N., and Panchenko, A. (2021): Methods for Detoxification of Texts for the Russian Language. In Proceedings of the 1st Workshop on NLP for Positive Impact (non-archival). The Association for Computational Linguistics and The Asian Federation of Natural Language Processing. Bangkok, Thailand (online).
- Babakov N., Logacheva, V., Kozlova, O., Semenov, N., Panchenko, A. (2021): Detecting Inappropriate Messages on Sensitive Topics that Could Harm a Company’s Reputation. In Proceeding of the 8th Workshop on Balto-Slavic Natural Language Processing (BSNLP 2021). The 2021 Conference of the European Chapter of the Association for Computational Linguistics. Kyiv, Ukraine (Online)
- Bondarenko, A., Fröbe, M., Beloucif, M., Gienapp, L., Ajjour, Y., Panchenko, A., Biemann, C., Stein, B., Wachsmuth, H., Potthast, M. Hagen, M. (2020): Overview of Touché 2020: Argument Retrieval. Working Notes of CLEF 2020 – Conference and Labs of the Evaluation Forum. Thessaloniki, Greece.
- Chekalina, V. and Panchenko, A. (2020): Retrieving Comparative Arguments using Deep Pre-trained Language Models and NLU. Working Notes of CLEF 2020 – Conference and Labs of the Evaluation Forum. Thessaloniki, Greece.
- Bondarenko, A., Hagen, M., Beloucif, M., Biemann, C., Panchenko, A. (2020): Answering Comparative Questions withWeb-based Arguments. Proceedings of AAAI 2020 Workshop on Interactive and Conversational Recommendation Systems, New York, USA
- Panchenko, A., Bondarenko, A., Franzek, M., Hagen, M., Biemann, C. (2019): Categorizing Comparative Sentences. Proceedings of the 6th Workshop on Argument Mining, Florence, Italy.
- Puzyrev, D., Shelmanov, A., Panchenko, A. and Artemova, E., (2019): A Dataset for Noun Compositionality Detection for a Slavic Language. In Proceedings of the 7th Workshop on Balto-Slavic Natural Language Processing (pp. 56-62).
- Arefyev, N., Sheludko, B., Davletov, A., Kharchev, D., Nevidomsky, A., Panchenko, A. (2019): Neural GRANNy at SemEval 2019 Task 2: A combined approach for better modeling of semantic relationships in semantic frame induction. Proceedings of SemEval 2019, Minneapolis, MN, USA [Winner of Task 2 and selected for best of SemEval session]
- Anwar, S., Ustalov, D., Arefyev, N., Ponzetto, S.P., Biemann C. and Panchenko, A. (2019): HHMM at SemEval-2019 Task 2: Unsupervised Frame Induction using Contextualized Word Embeddings. Proceedings of SemEval 2019, Minneapolis, MN, USA
- Panchenko A., Faralli S., Ponzetto S. P., and Biemann C. (2017): Using Linked Disambiguated Distributional Networks for Word Sense Disambiguation. In Proceedings of the Workshop on Sense, Concept and Entity Representations and their Applications (SENSE) co-located with the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL’2017). Valencia, Spain. Association for Computational Linguistics
- Pelevina M., Arefyev N., Biemann C., Panchenko A. (2016): Making Sense of Word Embeddings. In Proceedings of the 1st Workshop on Representation Learning for NLP co-located with the ACL conference. Berlin, Germany. Association for Computational Linguistics [Best paper award at the first workshop on representation learning for NLP]
- Ballweg K., Zouhar F., Wilhelmi-Dworski P., von Landesberger T., Fahrer U., Panchenko A., Yimam S.M. Biemann C., Regneri M., Ulrich H. (2016): new/s/leak – A Tool for Visual Exploration of Large Text Document Collections in the Journalistic Domain. Workshop on Visualisation in Practice co-located with the VIS conference, Baltimore, MD, USA
- Panchenko A., Faralli S., Ruppert E., Remus S., Naets H., Fairon C. Ponzetto S. P., and Biemann, C. (2016): TAXI at SemEval-2016 Task 13: a Taxonomy Induction Method based on Lexico-Syntactic Patterns, Substrings and Focused Crawling. In Proceedings of the 10th International Workshop on Semantic Evaluation. San Diego, CA, USA. Association for Computational Linguistics [Winner of SemEval-2016 Task 13 shared task]
- Kivimaki I., Panchenko A., Dessy A. Verdegem D., Francq P., Fairon C., Bersini H., Saerens M. (2013): A Graph-Based Approach to Skill Extraction from Text. In Proceedings of TextGraphs-8 Workshop co-located with the Conference on Empirical Methods for Natural Language Processing (EMNLP’2013). Seattle, USA. Association for Computational Linguistics
- Panchenko A. Morozova O. (2012): A Study of Hybrid Similarity Measures for Semantic Relation Extraction. In Proceedings of Workshop of Innovative Hybrid Approaches to the Processing of Textual Data Workshop co-located with the EACL’2012 conference, pp.10-18, Avignon, France. Association for Computational Linguistics
- Panchenko A, Beaufort R., Fairon C. (2012): Detection of Child Sexual Abuse Media on P2P Networks: Normalization and Classification of Associated Filenames. In Proceedings of Workshop on Language Resources for Public Security Applications of the 8th International Conference on Language Resources and Evaluation (LREC). European Language Resources Association (ELRA)
- Panchenko A., Adeykin S., Romanov P., Romanov A. (2012): Extraction of Semantic Relations between Concepts with KNN Algorithms on Wikipedia. In Proceedings of Concept Discovery in Unstructured Data (CDUD) workshop co-located with the International Conference On Formal Concept Analysis (ICFCA’2012), pp.78-88, Leuven, Belgium. CEUR-WS
- Panchenko A. (2012): Towards an Efficient Combination of Similarity Measures for Semantic Relation Extraction. Abstract in Proceedings of the 22nd Meeting of Computational Linguistics in the Netherlands (CLIN 22). Tilburg, The Netherlands. Tilgurg University
- Panchenko A. (2011): Comparison of the Knowledge-, Corpus-, and Web-based Similarity Measures for Semantic Relations Extraction. In Proceedings of the Workshop GEometrical Models of Natural Language Semantics (GEMS) co-located with the EMNLP’2011 conference. pp.10-18. Edinburgh, Scotland. Association for Computational Linguistics
- Panchenko A. (2010): Can We Automatically Reproduce Semantic Relations of an Information Retrieval Thesaurus?. In Proceedings of the Young Scientists Conference of the 4th Russian Summer School in Information Retrieval (RuSSIR’2010). pp.36–51. Voronezh, Russia. VSU
- Best paper award at the first workshop on representation learning for NLP (RepL4NLP) at the ACL 2016 conference in Berlin, Germany for the paper “Makings sense of word embeddings“, where an approach for inducing sense embeddings was presented.
- Best paper award of Fraunhofer IGD and Visual Computing Groups of TU Darmstadt (Darmstadt, Germany) in the category “Impact on the society” for the paper “new/s/leak – Information Extraction and Visualization for Investigative Data Journalists”. The paper presents an NLP system for investigative data journalism which was used by Der Spiegel journal.
- Best of SemEval-2019: our paper on unsupervised semantic frame induction using BERT was selected as one of the best submissions (with the possibility to present our work orally) at the 13th International Workshop on Semantic Evaluation (SemEval-2019) in Minneapolis, USA.
- Best presentation according to attendees of the AIST’2014 conference on gender detection in social media (slideshare).
- Two papers are accepted to the special issue of Semantic Web Journal (Q1) on Deep Learning for Knowledge Graphs (DL4KG). One is on taxonomy enrichment and the second one is a survey on neural entity linking.
- An invited talk at YaC/E: Yet Another Conference on Education in Yandex. Participation in a discussion on teaching data science courses and sharing my experience with teaching NLP course at Skoltech. Video.
- An invited talk at AI Technology In Search And Recommendation Workshop of Huawei on neural entity linking.
- An invited talk at AI Journey conference by Sberbank.
- A paper on text detoxification has been accepted to EMNLP-2021 on a collaborative project with MTS AI. See also a post at MTS blog about this line of research (in Russian).
- A lab at CLEF-2022 is accepted: Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality, and Visualization. Together with German colleagues I will be involved in the organisation of a shared task on argument retrieval.
- I chaired the NLP session at the Data Fusion conference. The video is available online.
- I received a DFG Merkator Fellowship (Visiting Professorships at German Universities) to perform a visit to Germany to work with researchers from Universities of Hamburg and Halle on comparative argument mining.
- An invited talk at the colloquium of Computer Science faculty of HSE on neural entity linking. The video is available online.
- Three papers has been accepted to the 16th conference of the European Chapter of the Association for Computational Linguistics (EACL) on active learning with pre-trained language models for sequence tagging, uncertainty estimation for transformer NLP models, and a demo paper on comparative question answering.
- A paper has been accepted to the 8th workshop on Balto-Slavic Natural Language Processing (BSNLP) co-located with the EACL-2021 conference on detection of inappropriate messages on sensitive topics that could harm a company’s reputation.
- An overview paper related to the CLEF laboratory on argument retrieval has been accepted to the 43rd European Conference on Information Retrieval (ECIR-2021).
- A paper has been accepted to the the 11th International Global Wordnet Conference (GWC2021) on graph-based representations for taxonomy enrichment (in collaboration with researchers from Moscow State University). Poster and video.
- Two papers have been accepted to the 28th International Conference on Computational Linguistics (COLING-2020) on neural lexical substitution (in collaboration with researchers from Samsung) and taxonomy enrichment.
- I am a co-organizer of the 9th international conference on Analysis of Images, Social Networks and Texts (AIST-2020).
- I am involved in the organization of the 14th workshop on graph-based natural language processing (TextGraphs-14) co-located with the 28th International Conference on Computational Linguistics (COLING’2020) in Barcelona, Spain.
- I co-organize a shared task on taxonomy enrichment at the Dialogue Evaluation campaign.
- A paper is accepted at the ECIR’2020 conference on Touché: The First Shared Task on Argument Retrieval.
- A paper accepted at the Web Search and Data Mining (WSDM’2020) conference on “Comparative Web Search Questions” in collaboration with several German researchers.
- I am involved in the organization of a CLEF 2020 lab on Argument Mining: consider participation in the shared tasks!
- Presentation at the panel discussion at the BUCC workshop at the RANLP’2019 conference.
- An invited talk at the AIST’2019 conference on several papers published in ACL and the associated workshops (conference web site).
- A paper is accepted at the international conference on Recent Advances in Natural Language Processing (RANLP’2019) in Varna, Bulgaria entitled “Combining Lexical Substitutes in Neural Word Sense Induction“.
- A paper is accepted at the 8th International Conference – Analysis of Images, Social networks and Texts (AIST’2019) in the main volume Springer LNCS on using distributional semantics for detecting noun compositionality.
- An invited talk at the Deep Pavlov lab at Moscow Institute of Physics and Technology.
- Seven papers accepted at ACL 2019 and associated workshops: three papers accepted to the main conference, one demo paper, a paper at the student research workshop (main conference) and two papers at regular workshops. This presentation provides summaries of all these papers and contains references to the pre-prints and codes.
- Two papers accepted at SemEval-2019 on unsupervised semantic frame induction in collaboration with Universities of Hamburg and Mannheim and in collaboration with Samsung research. In these two papers, ELMo and BERT contextualized word embedding models were probed in the task of semantic frame induction.
- A paper is accepted at the 8th Joint Conference on Lexical and Computational Semantics (*SEM) in Minneapolis, USA on learning graph embeddings based on graph similarity metrics.
- I co-organize a special issue in the Natural Language Engineering journal on “Informing Neural Architectures for NLP with Linguistic and Background Knowledge” together with Simone Paolo Ponzetto and Ivan Vulić.
- A keynote talk at the 24th International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2018): From unsupervised induction of linguistic structures to applications in deep learning.
- The best paper award in the category “Impact on Society” of Fraunhofer IGD and the Visual Computing Groups of TU Darmstadt for the paper “new/s/leak – Information Extraction and Visualization for Investigative Data Journalists“.
- I co-organize the 7th Conference on Analysis of Images, Social Networks, and Texts (AIST’2018). The selected papers will be published in the Springer LNCS series.
- An invited talk at the Global WordNet Conference (GWC’2018) in Singapore on inducing interpretable word senses for word sense disambiguation and enrichment of lexical resources.
- An article is accepted in the Natural Language Engineering article on graph-based distributional semantics.
- I co-organize a shared task on word sense induction for the Russian language. 18 teams participated in the task submitting 383 models. An overview of the results is available in this preprint.
- The release of a web-scale dependency-parsed corpus of English texts, based on the CommonCrawlweb crawls. The corpus features over 250 billion of tokens and is available at Amazon S3.
- The release of a web demo of the unsupervised, knowledge-free, and interpretable system for word sense disambiguation presented at EMNLP 2017 in Copenhagen.
Supervision of PhD Theses
- Özge Sevgili Ergüven (10.2018-…) is co-supervised with Chris Biemann (Germany). Özge is supported by DAAD (Deutscher Akademischer Austauschdienst) and is based at the University of Hamburg. Her PhD research is related to neural entity linking and representation learning on graphs.
- Saba Anwar (10.2018-…) is co-supervised with Chris Biemann (Germany). Saba is supported by DAAD (Deutscher Akademischer Austauschdiens) and the Higher Education Commission of Pakistan. Her PhD research is related to using of neural language models for unsupervised frame induction.
- Irina Nikishina (11.2019-…). Research of Irina is related to the development of methods for the automatic construction of lexical resources and the application of multilinear algebra to NLP.
- Daryna Dementieva (11.2019-…) Research of Daryna is related to the detection of fake news and textual style transfer.
- Victoriia Chekalina (11.2019-…) Research of Victoriia is related to comparative argument mining and multilinear algebra for NLP.
- Anton Razzhigaev (11.2020-…) Research of Anton is related to vectorization of knowledge graphs and question answering (KBQA).
Supervision of Master and Bachelor Theses
I supervised research-oriented Master theses, usually also aiming to publish a conference paper on the basis of the produced materials.
- Dmitry Puzyrev (2021, Skoltech).Policy-based strategies for active learning in a scalable setup. Co-supervised with Artem Shelmanov.
- Anton Voronov (2021, Skoltech-MIPT): Automatic Dialogue Censor – Style Transfer for Texts. Now with Sberbank AIR institute.
- Lyubov Kupriyanova (2021, Skoltech): Uncertainty Estimation for Active Learning and Misclassification detection in NLP. Co-supervised with Artem Shelmanov.
- Vitaly Protasov (2021, Skoltech-MIPT): Cross-lingual lexical substitution. Now with Sberbank AIR institute.
- Denis Teslenko (2020, Ural Federal University): Multilingual Graph-based Word Sense Disambiguation with Word Embedding Only.
- Heike Heller (2019, University of Hamburg): Comparative Query Suggestion. Co-supervised with Chris Biemann.
- Dmitry Puzyrev (2019, Higher School of Economics, CS faculty): Supervised Approaches to Detection of Noun Compositionality. Co-supervised with Artem Shelmanov and Ekaterina Artemova.
- Matthias Schildwächter (2019, University of Hamburg): An Open-Domain System for Retrieval and Visualization of Comparative Arguments from Text.
- Alvin Rindra Fazrie (2019, University of Hamburg): Visual Information Management with Compound Graphs. Main supervisor: Steffen Remus.
- Dahmash Ibrahim (2018, University of Hamburg): Question Answering using Dynamic Neural Networks. Main supervisor: Benjamin Milde.
- Mirco Franzek (2018, University of Hamburg). Comparative Argument Mining. Co-supervised with Chris Biemann.
- Marten Fide (2017, TU Darmstadt). Predicting hypernyms in contexts with JoBimText. Co-supervised with Chris Biemann. Now at TU Darmstadt.
- Maria Pelevina (2016, TU Darmstadt). Unsupervised Word Sense Disambiguation with Sense Embeddings. Co-supervised with Chris Biemann. Now at Deutsche Bahn R&D.
- Simon Dif (2015, TU Darmstadt). Statistical Models of Semantics with Structured Topics. Co-supervised with Chris Biemann. A dual degree Masters program with ENSIMAG, Grenoble, France. Now at Altran R&D.
- Alexey Romanov (2012, Moscow State Technical University). Graph Algorithms in the Lexical Semantic Search Engine ‘Serelex’. Co-supervised with Andrew Philippovich. Now at the University of Massachusets Lowell.
Internships & Visiting Researchers
I help to write research proposals to funding organizations which let researchers visit our faculty and do interesting short-term research project together.
- Dmitry Puzyrev (2019): Using hyperbolic word embeddings for detection of noun compositionality. Partially funded by the University of Hamburg. Visit outcome: ACL publication.
- Shantanu Acharya (2018): Taxonomy induction using word sense representations. Funded by DAAD. Visit outcome: ACL publication.
- Andrey Kutuzov (2018): Learning graph embeddings via node similarities. Funded by the University of Oslo. Visit outcome: ACL and *SEM publications.
- Artem Chernodub (2017): Recurrent Neural Networks for Argument Mining. Funded by DAAD. Visit outcome: ACL demo paper.
- Dmitry Ustalov (2016): Graph Clustering for Word Sense Induction. Funded by DAAD. Visit outcome: ACL and EACL publications.
- Statistical Natural Language Processing (Spring, 2019). A course for Master students. Slides. The course is based on the classic textbook of Jurafsky & Martin and represents a set of topics on (mostly) pre-neural NLP.
- Neural Natural Language Processing (Winter, 2019). A course for Master students. Slides. This course is focusing mostly on neural NLP models.
- A guest lecture at the Deep Learning for Natural Language Processing course at Indian Institute of Technology (IIT) Patna, India on “Word and document embeddings” (Winter, 2020).
Organization of Events
- NLIWoD: workshop on Natural Language (NL) Interfaces to the Web of Data co-located with the 2022 European Semantic Web Conference (ESWC).
- QALD-10: Question Answering over Linked Data challenge.
- TextGraph-16: workshop on graph-based natural language processing co-located with the 29-th International Conference on Computational Linguistics (COLING-2022) in Gyeongju, Republic of Korea
- Touché-3: The 3rd shared task on argument retrieval at the CLEF 2021 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality, and Visualization. Bologna, Italy.
- RuArg-2022: The first shared task on argument mining for the Russian language at Dialogue Evaluation forum.
- RUSSE-2022: shared task on text detoxification for the Russian language at Dialogue Evaluation forum.
- Touché-2: The second shared task on argument retrieval at the CLEF 2021 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality, and Visualization. Bucharest, Romania.
- TextGraphs-15: workshop on graph-based natural language processing co-located with the annual meeting of the North American Chapter of the Association of Computational Linguistics (NAACL-2021) in Mexico City, Mexico.
- Knowledgeable NLP: The first workshop on integrating structured knowledge and neural networks for NLP co-located with the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 9th International Joint Conference on Natural Language Processing (AACL-IJCNLP-2020).
- AIST-2020: The 9th International Conference on Analysis of Images, Social Networks, and Texts.
- TextGraphs-14: workshop on graph-based natural language processing co-located with the 28th International Conference on Computational Linguistics (COLING’2020) in Barcelona, Spain.
- Dialogue Evaluation 2020 shared task on taxonomy enrichment for the Russian language. Codalab.
- Touché: The 1st shared task on Argument Retrieval at the CLEF 2020 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality, and Visualization Thessaloniki, Greece.
- Special issue of Natural Language Engineering journal on informing neural architectures for NLP with linguistic and background knowledge.
- RUSSE-2018: Shared task on Word Sense Induction for the Russian Language (RUSSE’2018). This is a part of the Dialogue 2018 conference on Computational Linguistics.
- AIST 2014, 2015, 2016, 2017, 2018: Conference on Analysis of Images Social Networks and Texts (AIST), area chair of the Natural Language Processing track. I was involved in the organization of the conference and edition of the proceedings published by Springer CCIS series in 2014, 2015 and 2016, 2017, and 2018. In 2019 I am a part of the steering committee at AIST. In 2020 and 2021 I acted as the program chair of the conference coordinating the organization of the event hosted by Skoltech.
- CDUD: The 3rd International Workshop on Concept Discovery in Unstructured Data (CDUD) co-located with the 13th International Conference on Concept Lattices and Their Applications
- RUSSE: The First International Workshop on Russian Semantic Similarity (RUSSE) co-located with the 20th International Conference on Computational Linguistics Dialogue’2015. See also the website with the description of the shared task and the datasets.
Presentations and Invited Talks
- An invited talk at AI Technology In Search and Recommendation Workshop by Huawei on neural entity linking.
- An invited talk at AI Journey by Sber on neural entity linking.
- An invited talk at Moscow State University AI conference.
- An invited talk at FENIST Scientific Festival.
- Presentation at the Huawei NLP Workshop on taxonomy enrichment.
- Presentation at the panel discussion at the BUCC workshop at the RANLP’2019 conference.
- Invited talk at the AIST’2019 conference on several papers published in ACL and the associated workshops (conference web site).
- Invited talk at the Deep Pavlov lab at Moscow Institute of Physics and Technology.
- Keynote talk at the 24th International Conference on Computational Linguistics and Intellectual Technologies (Dialogue’2018): From unsupervised induction of linguistic structures to applications in deep learning (presented first at a seminar in Skoltech).
- Invited talk at the Global WordNet Conference (GWC’2018) in Singapore on inducing interpretable word senses for word sense disambiguation and enrichment of lexical resources.
Area Chair for Conferences
- European Chapter of the Association for Computational Linguistics (EACL-2021). Area chair in the field of lexical semantics.
Programme Committee for Conferences and Workshops
- ICLR: International Conference on Representation Learning (2021)
- NeurIPS: Conference on Neural Information Processing Systems (2021)
- BSNLP: Workshop on Balto-Slavic Natural Language Processing (2021)
- EACL: European Chapter of the Annual Meeting of the Association of Computational Linguistics (2019, 2021)
- BIAS: International Workshop on Algorithmic Bias in Search and Recommendation co-located with the 42nd European Conference on Information Retrieval, ECIR (2020)
- ISCW: International Conference on Computational Semantics, ACL SIGSEM special interest group on semantics (2019)
- CoNLL: The SIGNLL Conference on Computational Natural Language Learning (2018, 2019)
- ACL: Annual Meeting of the Association for Computational Linguistics (2018, 2019, 2020)
- *SEM: Joint Conference on Lexical and Computational Semantics (2018, 2019)
- NAACL: North American Chapter of the Association for Computational Linguistics: Human Language Technologies (2018, 2019)
- SocInfo: Social Informatics international conference (2018)
- CLL: 3rd Workshop on Computational Linguistics and Language Science (2018)
- EMNLP: The Conference on Empirical Methods on Natural Language Processing (2017, 2018, 2019, 2020)
- ESWC: The Semantic Web conference (2017, 2018)
- ASSET: Workshop on Advanced Solutions for Semantic Extraction from Texts co-located with the ESWC conference (2017)
- TextGraphs: Workshop on Text Graph co-located with the ACL/EMNLP/NAACLconferences (2016, 2017, 2018, 2019)
- ReprL4NLP: Workshop on Representation Learning for NLP co-located with the ACL conference (2017, 2018).
- SMERP: International Workshop on Exploitation of Social Media for Emergency Relief and Preparedness (co-located with 39th European Conference on Information Retrieval, ECIR (2017)
- COLING: International Conference on Natural Language Processing (2016, 2018)
- AINL: Conference on Artificial Intelligence and Natural Language (2015, 2016, 2017)
- SEMANTiCS: International Conference on Semantic Systems (2016, 2017)
- Dialogue: International Conference on Computational Linguistics (2015, 2016, 2017, 2018)
- RECITAL: Rencontre des Étudiants Chercheurs en Informatique pour le Traitement Automatique des Langues, co-located with TALN conference (2015, 2016, 2017)
- NLDB 2015, 2016, 2017, 2022: International Conference on Natural Language & Information Systems
- WI: IEEE/WIC/ACM International Conference on Web Intelligence (2014, 2015)
- RuSSIR: Young Scientists Conference at Russian Summer School in Information Retrieval (2014, 2015)
- AIST: Conference on Analysis of Images, Social Networks, and Texts (2014, 2015, 2016, 2017, 2018)
- RANLP: Conference on Recent Advances in Natural Language Processing (2013, 2015, 2019)
- LTC: The Language and Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics (2011, 2013)
- CANI: a workshop of International Joint Conferences on Artificial Intelligence, IJCAI (2020)
Journal Reviewing
- Machine Learning. Springer-Nature (2021)
- Journal of Machine Learning Research (JMLR), MIT press (2020)
- Information Processing & Management, Elsevier (2018, 2019, 2020)
- Language Resources & Evaluation, Springer (2018, 2019, 2020, 2021)
- PLOS ONE (2018)
- Natural Language Engineering, Cambridge University Press (2018)
- Data & Knowledge Engineering (DATAK), Elsevier (2017, 2018)
- International Journal of Artificial Intelligence and Soft Computing, Interscience (2016)
- Internet Computing Journal, IEEE (2015)
- International Journal of Child Abuse & Neglect, Elsevier (2014)
Reviewing of Ph.D. Dissertations
- “Linguistic interpretation and evaluation of word vector models for the Russian language” by Tatiana Shavrian, Higher School of Economics
- “Advancing Lexical Substitution via Automatically Built Resources and Generative Approaches” by Caterina Lacerra, Sapienza Università di Roma
- “Specialisation of language models for the natural language processing tasks” by Yuri Kuratov, Moscow Institute of Physics and Technology
- “Methods of Network Embeddings and their Applications” by Ilya Makarov, University of Ljubljana
- “Combinatorial and neural graph vector representations” by Sergei Ivanov, Skolkovo Institute of Science and Technology
- “Knowledge-based approaches to producing large-scale training data from scratch for Word Sense Disambiguation and Sense Distribution Learning” by Tomasso Passini, Sapienza Università di Roma
- “Methods for compression of neural networks for natural language processing”, Artem Grachev, Higher School of Economics
Reviewing of Master Dissertations
- Grigory Arshinov (2021): Knowledge graph based question answering dataset for Russian. Higher School of Economics (Faculty of Computational Linguistics)
- Boris Sheludko (2021). Lexical substitution methods for NLP tasks. Moscow State University (Faculty of Computing Sciences and Mathematics)
- Maxim Fedoseev (2021): Methods for building vector representations of word senses in context. Moscow State University (Faculty of Computing Sciences and Mathematics)
- Adis Davletov (2021): Methods for extraction of information from definitions of words. Moscow State University (Faculty of Computing Sciences and Mathematics)